
Since May 20th many internet sites that Search engines deems ‘bad’ in quality could have found themselves ranking lower in serps, potentially failing to keep visitors and income. That was the day the big G began rolling out Panda 4.0, the latest main Panda upgrade, that is push to boost the product quality and relevance of web-pages it shows in its search results.
What has been the impact of the latest modification? And how exactly does Google begin judging quality content – determining and punishing websites that don’t meet its criteria? And what goes on when it will get things wrong?
Panda 4.0 Case Study – A Severe Panda 4.0 Hit http://t.co/vIeCFe09SS #seo pic.twitter.com/j961Z6hgm2
— AJ Ghergich (@SEO) June 17, 2014
The most recent modification to Google’s “special secret recipe”
Panda 4.0 may be the latest modification to Google’s formula, the ‘top secret sauce’ that determines which web pages will show up in the results first. And these updates, alongside many smaller sized iterations, certainly are a key portion of Googles armory since it seeks to continuously improve its capability to provide searchers with relevant outcomes, pushing low quality, spammy content further down.
The initial Panda modification was implemented by Google in January 2011 and consecutive Pandas, and also other algorithm updates have affected many sites that do not pass Google’s high quality check with devastating impact. The chart beneath displays the declining visibility in searches for one particular site, very obviously illustrating the development of Google’s algorithm – with the perpendicular dips revealing the main Panda 2.0 revise that resulted in a steep rank fall, alongside smaller sized Panda iterations.
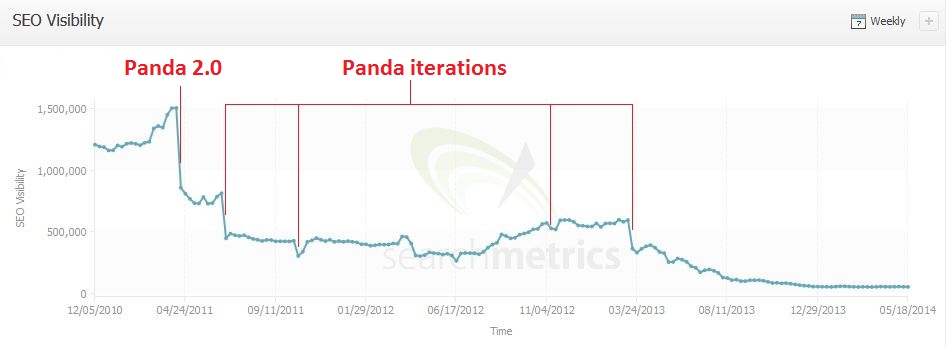
Aggregator websites negatively impacted after Panda 4.0
It grew to become apparent that aggregator internet sites – those that aggregate info from other web sources instead of posting their own original content – have already been among the key targets this time around. This includes Push portals, News websites (especially the superstar/ gossip field which republish stories from news organizations), Price Assessment sites in addition to some Discussion boards and Weather conditions portals.
It seems sensible that Search engines should target websites that do not display original content – in the end it is attempting to present outcomes which will be the optimum solution to searchers’ queries, not the ones that are already obtainable in numerous different locations.
The features of a superior quality web page?
But what’s Google’s definition of a top quality page and how exactly does a search engine differentiate higher from poor web pages, given the incredible number of pages it must sift through?
A good response to the initial question are available in an articles that Google itself posted on the Webmaster Central blog site in 2011 under the headline “What matters as a high-quality web site?“. Some essential extracts are:
- Can you trust the info presented in this post?
- Are the subjects driven by legitimate interests of visitors of the website, or does the website generate content material by guessing what might rank nicely?
- Does this article give a complete or extensive description of this issue?
- Does the web page provide substantial worth in comparison with other pages in the results?
- Is this the type of web page you’d desire to bookmark, tell a friend, or recommend?
So a few of the main features that Search engines feels are essential to the grade of a website are; trust, worth, created for searchers (instead of 2nd guessing what might position nicely), comprehensively covering a subject and originality. They are elements the majority of searchers may possibly use to determine an excellent page.
So how does Google differentiate higher quality from poor?
To answer the next question, you need to understand that there are hundreds of factors that Google’s algo analyzes when determining what sort of page should rank in search engines for specific queries. These range from whether the words and phrases on the web page match the ‘keywords’ in the query, the presence of pictures, whether other sites have linked to a page, site speed, presence of spelling errors etc.
But importantly in relation to rating the standard of a full page, Google furthermore analyzes ‘user indicators’. Basically it compares how searchers interact with a page to assess how well it has met their requirements. These user indicators include Click-Through Rate, SERP Return Rate (the proportion of searchers heading back to the search engine results after visiting the site – which implies they didn’t find what they were looking for) and Time on Site (if searchers remain longer this implies the web page is what they were searching for).
Therefore Google’s algorithm instantly positions webpages within results predicated on a huge selection of factors including consumer signals. Updates such as for Panda are types of modifications to the algorithm that may lead to huge shifts in search positions for a few sites. And Google is continuously testing and enhancing their algorithms, an activity so fundamental to the company, it has been given a special name: The Google Everflux.
What happens when the algorithm will get it wrong?
The algorithm is founded on software technology so therefore can be an objective assessor of quality. But you can find instances where Google believes the algorithm got it wrong. Basically sites that have infringed its recommendations still rank greater than they should.
Because of this the Search giant employs human raters. Google’s Research Quality team, directed by Matt Cutts, rates internet sites ‘by hand’ utilizing the so-called Quality-Rater-Recommendations (which – just like the factors found in the algorithm – are usually ” inside info “).
This team gets the capacity to unleash a Google Penalty, a measure that may lower or get rid of the search positions of certain webpages of websites that violate Google’s guidelines (despite the fact that they could otherwise rank nicely by the algorithm).
Can people objectively judge quality?
You can find domains which have never been released from their manual penalty and forced to survive on little or no search visitors. And you can find domains that have been penalized no longer turning up for their own brand searches. Something similar to this occurred to the domain of the German car manufacturer BMW not long ago. It is difficult to argue that this could be good for searchers.
So even though many of the search giant’s detractors can accept the target justice of algorithm updates such as Panda 4.0, they occasionally point the finger accusingly with regards to manual Search engines penalties. They state: algorithms are usually objective naturally. But humans aren’t and can’t be relied on to objectively judge the product quality and relevance of web pages. And how do Search engines justify overruling its automated, highly delicate algorithm in this manner?
Ultimately needless to say Google decides who’s permitted to play the overall game. Even though Panda 4.0 along with other updates are portion of the evolution and fine tuning of the algorithm, it really is unlikely to be perfect. Human quality raters will persist. And whether it’s the algorithm or the Research Quality group that’s wielding the power, businesses will have to try to play by the guidelines.